
When we look at the world from the perspective of distributed, discontinous, and highly disparate data, it is easy to forget that it runs on structures. This is the one key challenge of data science. It is similar to natural language spanning different cultures. As an example, when we hear a new language, it will first sound unstructured because we are unable to decode it. But before attempting to understand it, it is important to understand the underlying encoded structure. Thus, the most significant step in comprehending that language is to first decode the fundamental structure.
In the world of data, there are two categories: 1/Structured data and 2/Unstructured data. Structured data comes with a defined relational schema, while unstructured data lacks one, making it difficult to administer, query, and use across a span. With structured data, defining a schema benefits by enabling broad-scope queries across a range of relational datasets.
While Language Models have transformed our ability to do more with unstructured data, such as ingesting a file and using an LLM to understand deeper structures, there are architectural challenges that limit an organization’s ability to scale its reliance on LLMs to turn unstructured data into a queryable dataset. Additionally, as we have written in previous blogs, RAG is not a sufficient architectural primitive to turn more unstructured data into a scalable artifact.
Deconstruction Process
There is a progression from data to knowledge. This progression is predicated on relational values between data. Information is derived when data relates to other data. For example, in the sentence “my car is black”, none of the words in that sentence can be considered information on its own.
This is why understanding natural language is critical in information engineering, which now underpins Generative AI. Although Retrieval Augmented Generation (RAG) addresses retrieval optimization through vectorization, it leaves a gap by being blind to the structure that binds the data into information.
A good article on this topic was published by Towson University - "Elements of Sentence Construction" (https://webapps.towson.edu/ows/sentelmt.htm), which sheds light on how to approach information engineering. The article breaks a sentence into two parts: the subject and the predicate. But functionally, we can break it down further into the following:
- Subject - Who or What
- Verb - What is happening
- Object - What is affected
- Complements - Describes the what (Subject)
While this fundamental understanding of sentence structure is important for training a large language model with attention spanning the whole sentence to better derive context, there has been less emphasis on how to extend this to the ingestion process when building a knowledge system.
For the Syncratic Federated Knowledge and Assurance System, we adopted a deconstruction approach that applied evenly across the information journey. Right from ingestion, we build a semantic and relational understanding of the information to heavily optimize the context window, with the sole purpose of keeping answers grounded, thereby reducing the risk of hallucination.
Clustering the Relationships
To further enhance the knowledge evolution process, we applied clustering algorithms to efficiently create dense communities of well-connected information clusters across large datasets. This algorithm helps to create:
- Identify latent but connected knowledge pockets
- Establish cross-document, cross-entity patterns
- Build communities that continuously highlight knowledge evolution (movement, refinement, and relational value)
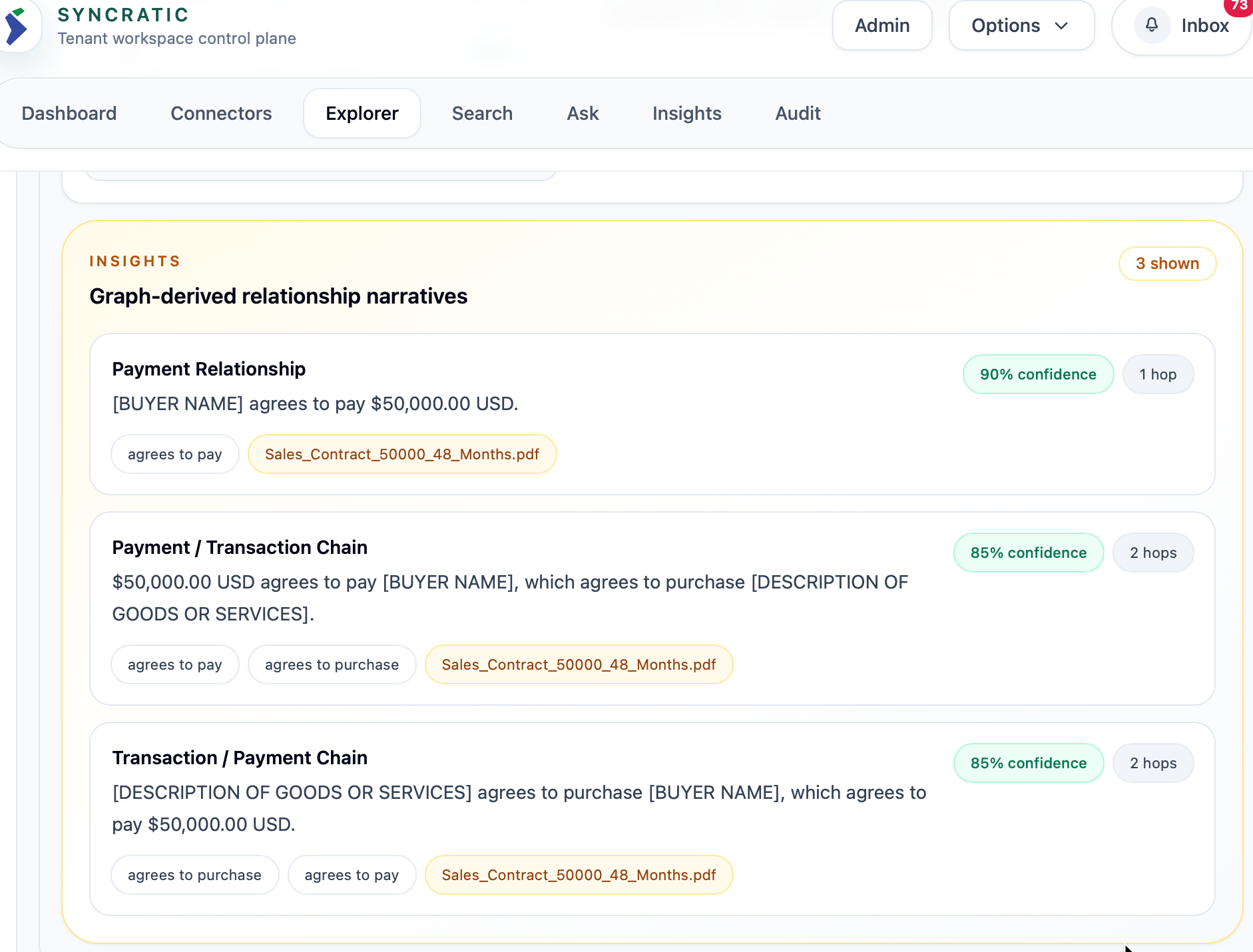
Image 1: Latent knowledge forming community candidates.
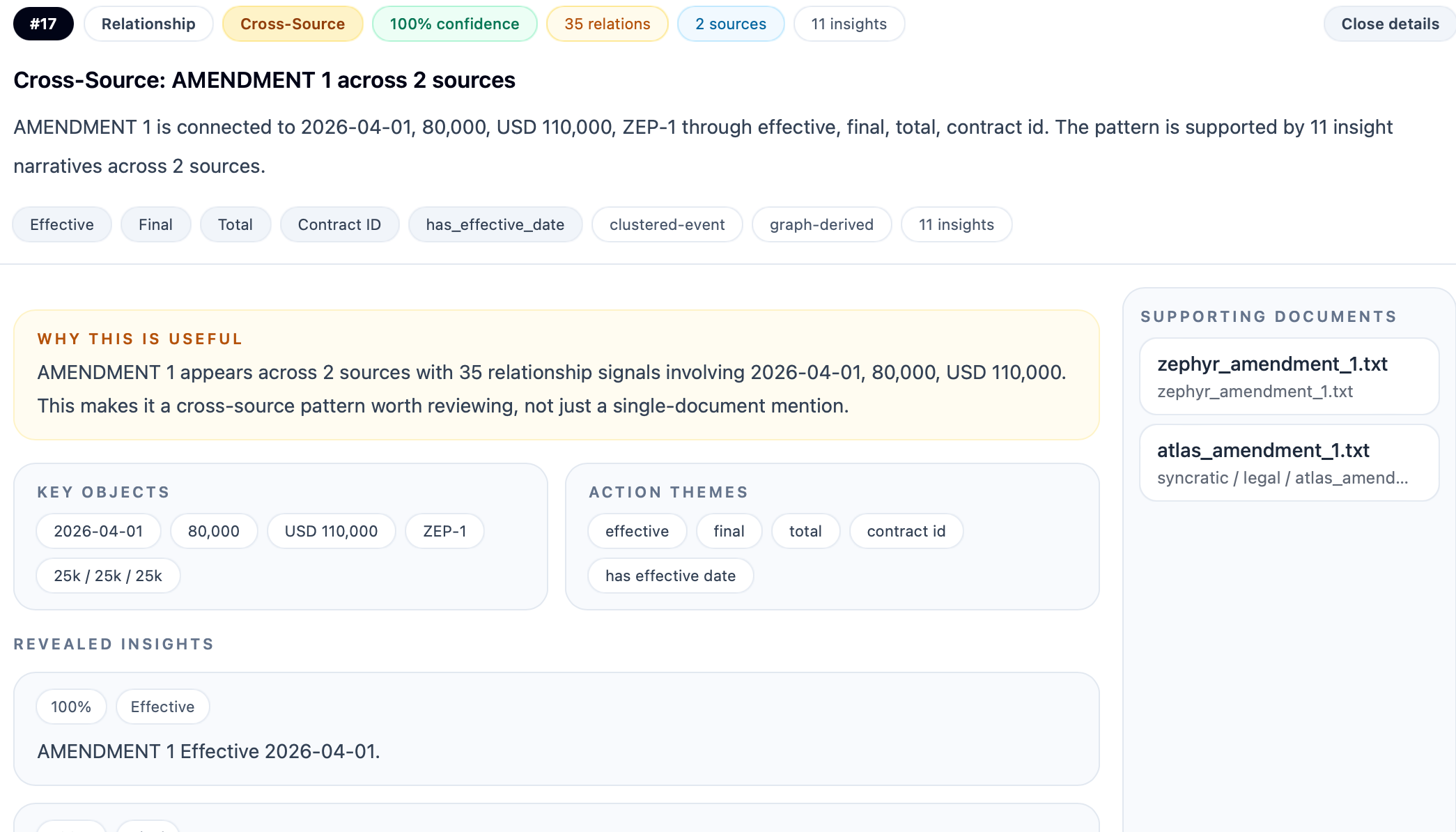
Image 2: Revealing the evolution of a contract
This helps each community to bind across:
- Which entities belong together
- Which relation families dominate
- Which documents support the cluster
- What is the likely significance? Insights!
Close
The functional application of a knowledge engine built on decomposition and reconstructuon of information can include revealing document evolution (e.g., redlining, document upgrades), synthesizing siloed data, making knowledge readily available across a large data set, and putting humans right at the center of organizational knowledge evolution.