
Technological breakthroughs often arise from architectural change. A prime example is the Transformer, which introduced 'self-attention' in 2017 to replace Recurrent Neural Networks (RNNs). While RNNs processed text sequentially, the Transformer’s architecture enabled models to process every word in a sentence simultaneously, fundamentally reorganizing how data is contextualized. This structural shift created the vast 'context window' that defines modern Large Language Models.
However, the context window, by itself, also has a hard limit, and because the LLM is stateless, that limit required its own solution. Enter Retrieval-Augmented Generation (RAG). The success of RAG (chunk-first) enabled us to scale LLM use and extend context into long-term memory. But gradually, the RAG architecture itself became an accepted liability in LLM implementation because it relies on vector-based representations that require finding similar chunks, increasing the risk of hallucinations.
One of the challenges in applying Large Language Models is trust. Because LLMs tend to hallucinate, they are perceived as liabilities that must be used with caution in critical use cases with no tolerance for error. The legal sector is a perfect example. Legal documents must be treated with the highest level of integrity, and that integrity must be preserved throughout all content processing. Each document’s referential integrity must be preserved.
But in the traditional RAG workflow, parsing the document content provided a fast, efficient way to handle sequential contexts.
Traditional RAG Process:
Document → Chunk → Embed → Store → Retrieve → Generate
In that RAG architecture, Generate is where the models are used. The issue in this flow is not the model's reasoning capacity. It is the architecture surrounding it. By embedding text fragments before semantic interpretation, chunk-first RAG compresses meaning into vectors before understanding document structure, intent, or internal dependencies. Retrieval must then reconstruct meaning probabilistically at query time.
This creates structural liabilities:
⁃ Semantic fragmentation
⁃ Loss of referential continuity
⁃ Over-reliance on similarity heuristics
⁃ Increased hallucination risk due to partial context
⁃ Weak auditability of reasoning paths
The question is: if LLMs can reason from data, then retrieval systems should align with their reasoning outputs. Why not leverage LLM capabilities to eliminate the need for chunking? In a ‘semantic file system’ use case, we introduced the following workflow:
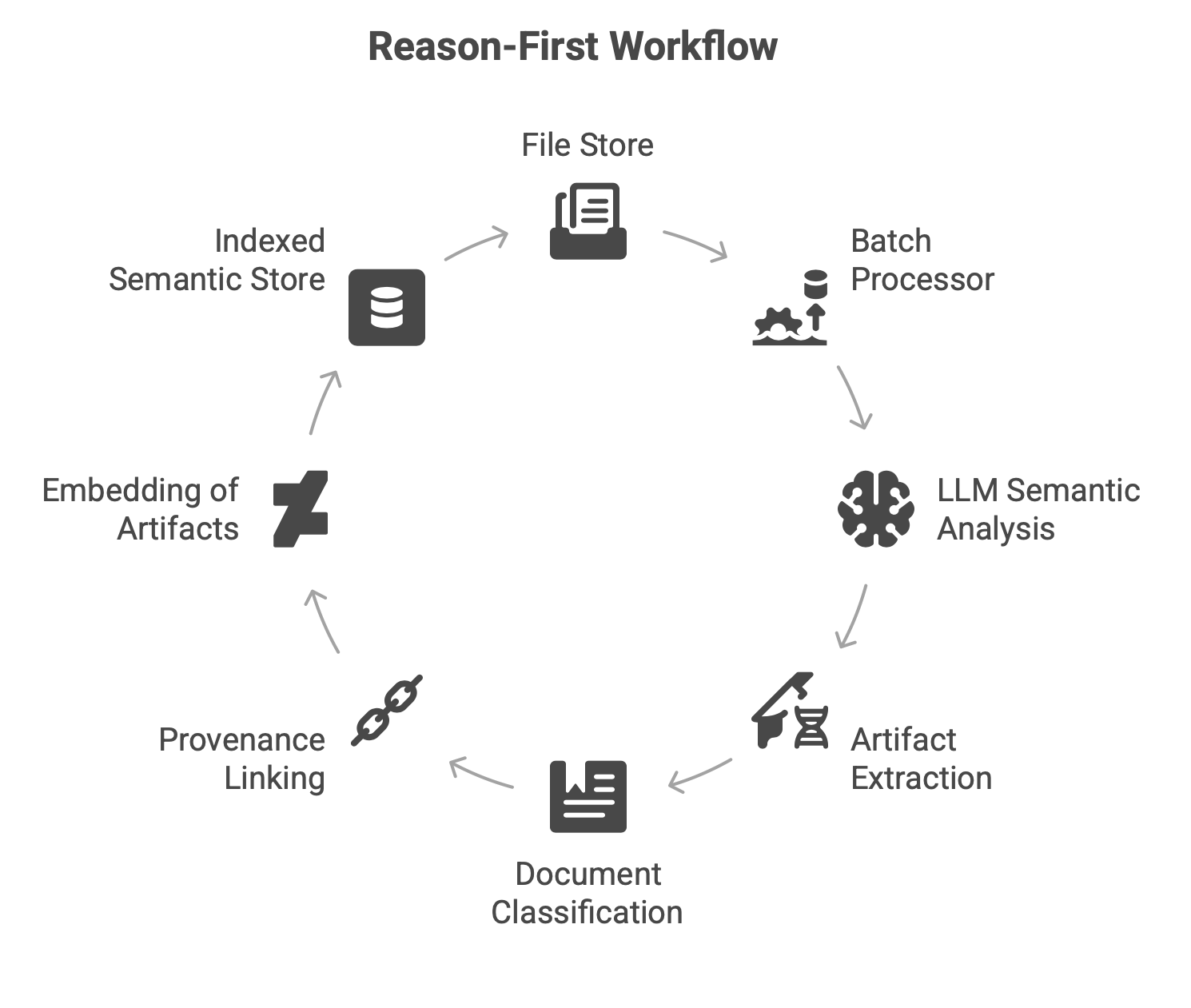
At a fundamental level, the Transformer architecture introduced more than scale — it redefined how models extract structure from data. For decades, machine learning systems relied on supervised pipelines in which humans engineered features and manually labeled data to approximate semantic understanding. Feature extraction became a specialized engineering discipline.
Large Language Models have changed this dynamic. Through large-scale self-supervised training, they internalize representations that enable them to reason about text, infer structure, and perform classification without bespoke feature engineering.
In effect, LLMs perform three core operations at scale:
1. Reason
2. Understand
3. Classify
These advanced capabilities represent a structural leap in machine learning — shifting intelligence from manually crafted pipelines to generalized semantic inference, or, better put, to intelligent automation.
Trade-offs
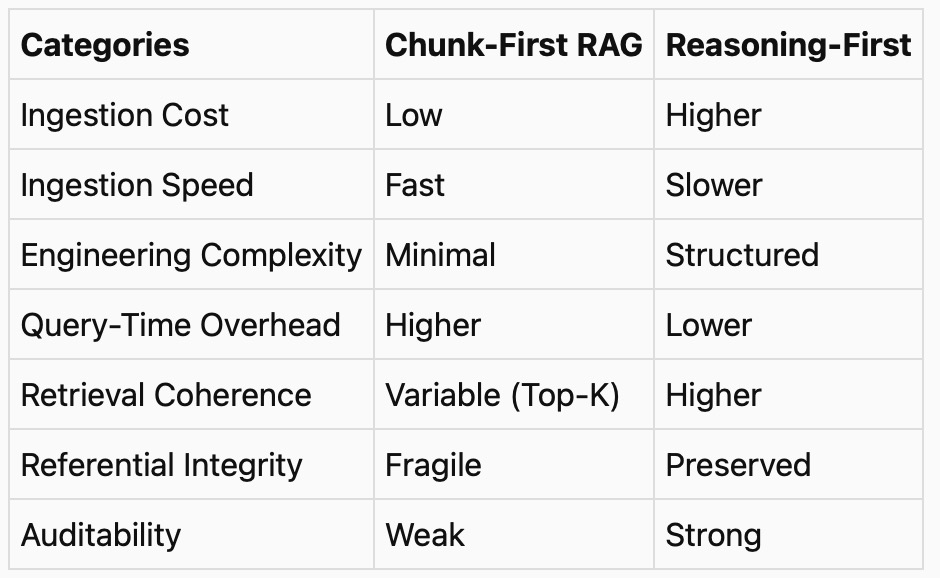
Reason-first architecture is not without its trade-offs. First, the use cases must be sufficiently understood within the applicable domain. To break it down, reason-first is essential in domains where the cost of hallucination is high. Consider the legal sector, contract negotiations, financial analysis, and risk modeling. Such domains highly value the following:
1. Provenance - the documented history of the data, such as its origin, transformations over time, and location.
2. Auditability - log events attributed to the data: who, what, when, and why (context).
3. Integrity - while reasoning is used for classification, the data must be inference-free. This limits the risks of hallucinations.
The chunk-first approach was intended to address problems caused by token consumption during ingestion, which can be slow and costly when language models are used. RAG enabled fast sorting and graph-based data mapping, which, in turn, enabled fast and scalable querying. As the cost of LLMs declines, the use cases for reason-first approaches will expand.
The table below provides clear contrasts between traditional RAG and reason-first architecture:
Support Artifacts
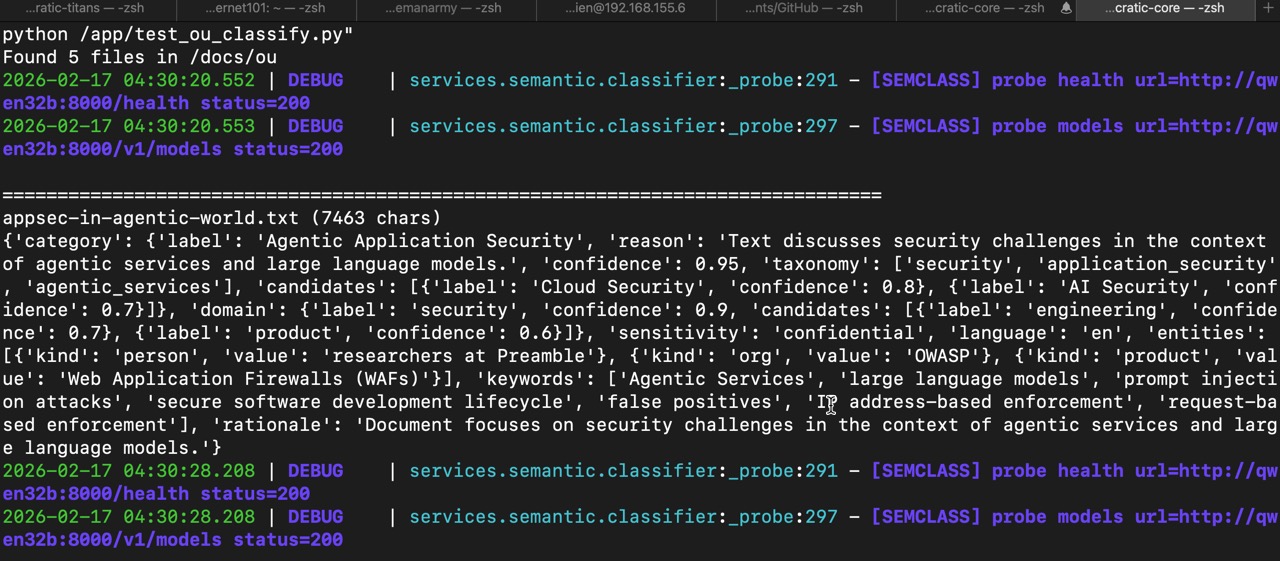
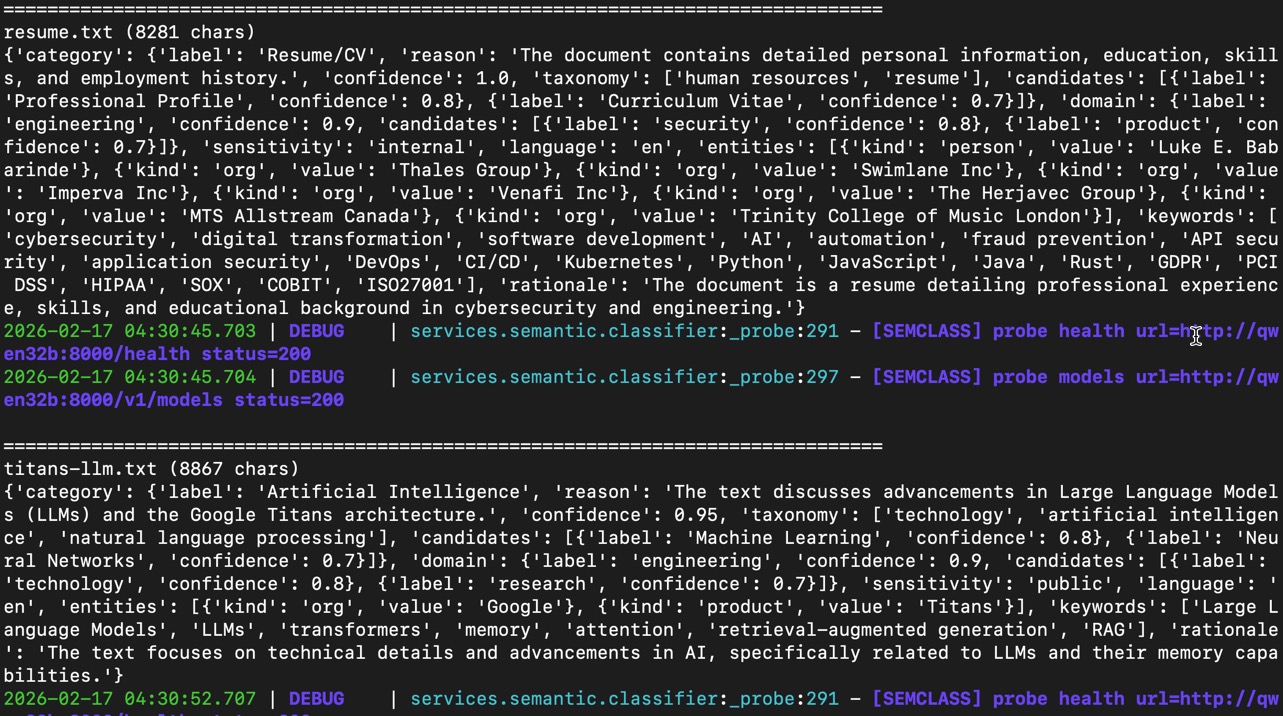
Below are examples of outputs from semantic_classification which demonstrates the structured output of the classification process using reasoning.
Snippet of the classifier function:
async def classify_document_text(*, text: str, filename: str = "") -> SemanticClassification:
"""
Semantic classification with robust URL handling.
Environment:
- CHAT_URL or LLM_URL can be:
http://qwen32b:8000
http://qwen32b:8000/v1
http://qwen32b:8000/v1/chat/completions
http://qwen32b:8000/v1/completions
- DEFAULT_MODEL default: qwen32b
"""
raw = os.getenv("CHAT_URL") or os.getenv("LLM_URL") or "http://qwen32b:8000"
base, mode = _normalize_llm_url(raw)
model = os.getenv("DEFAULT_MODEL", "qwen32b")
api_key = os.getenv("OPENAI_API_KEY")
user_content = f"FILENAME: {filename}\n\nTEXT:\n{text}\n"
timeout = _timeout()
async with httpx.AsyncClient(timeout=timeout, trust_env=False, http2=False) as client:
if os.getenv("SEMCLASS_PROBE", "1") == "1":
await _probe(client, base, api_key)
headers = _headers(api_key)
# Prefer chat unless the user explicitly configured completions
try:
if mode == "chat":
url = _join_v1(base, "chat/completions")
payload = {
"model": model,
"messages": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
"temperature": 0.0,
"max_tokens": 700,
"stream": False,
}
r = await client.post(url, headers=headers, json=payload)
if r.status_code >= 400:
logger.error(f"[SEMCLASS] LLM error {r.status_code} url={url} body={r.text}")
return _fallback(f"fallback:llm_http_{r.status_code}")
data = r.json()
content = (((data.get("choices") or [{}])[0].get("message") or {}).get("content")) or ""
obj = _extract_json(content)
return _parse_result(obj)
if mode == "completions":
url = _join_v1(base, "completions")
prompt = _messages_to_prompt(SYSTEM_PROMPT, user_content)
payload = {
"model": model,
"prompt": prompt,
"temperature": 0.0,
"max_tokens": 700,
"stream": False,
}
r = await client.post(url, headers=headers, json=payload)
if r.status_code >= 400:
logger.error(f"[SEMCLASS] LLM error {r.status_code} url={url} body={r.text}")
return _fallback(f"fallback:llm_http_{r.status_code}")
data = r.json()
text_out = ((data.get("choices") or [{}])[0].get("text")) or ""
obj = _extract_json(text_out)
return _parse_result(obj)
# mode == "responses"
url = _join_v1(base, "responses")
payload = {
"model": model,
"input": [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_content},
],
"temperature": 0.0,
"max_output_tokens": 700,
}
r = await client.post(url, headers=headers, json=payload)
if r.status_code >= 400:
logger.error(f"[SEMCLASS] LLM error {r.status_code} url={url} body={r.text}")
return _fallback(f"fallback:llm_http_{r.status_code}")
data = r.json()
text_out = ""
try:
out0 = (data.get("output") or [])[0]
c0 = (out0.get("content") or [])[0]
text_out = c0.get("text") or ""
except Exception:
text_out = ""
obj = _extract_json(text_out)
return _parse_result(obj)
except (httpx.TimeoutException,) as exc:
logger.error(f"[SEMCLASS] timeout mode={mode} base={base} exc={type(exc).__name__} {repr(exc)}")
return _fallback("fallback:timeout")
except Exception as exc:
logger.error(f"[SEMCLASS] http_error mode={mode} base={base} exc={type(exc).__name__} {repr(exc)}")
return _fallback("fallback:http_error")